

Bilgisayarla İstatistik Uygulamaları Ders Notları
20 Kasım 2024 – Ahmet Uluca
Üniversitelerde ders olarak okutulan Bilgisayarla İstatistik Uygulamaları Ders Notlarına aşağıda yer verdim. Sınavda soru olarak çıkabilecek yerlere (Benim dönemim de soru çıkan yerleri) not düştüm.
Diğer derslere sayfanın en altındaki linklerden veya üst ile alt menüde bulunanan site içi arama düğmesinden ulaşabilirsiniz. Sayfanın en altındaki yorumlar kısmından sorularının veya notlarının eklenmesini istediğiniz dersleri bildirirseniz en kısa zamanda eklerim.
HAFTA 2: Temel İstatistik Kavramlari
İstatistik nedir?
Belirli bir amaç için verilerin toplanması, sınıflandırılması, çözümlenmesi, ve sonuçların yorumlanması ile ilgili teknik ve yöntemleri içeren bir bilim dalıdır.
Veri Nedir?
Veri, ham gerçek enformasyon parçacığına verilen adder. Ölçüm ya da sayım yolu ile toplanan ve sayısal bir değer bildiren veriler nicel veriler, sayısal bir değer bildirmeyen veriler de nitel veriler olarak adlandırılmaktadır.
Büyük Veri Nedir? (Big Data)
Normalde büyük veri nin belli bir satır yada sütundan oluşur diye bir kıstası yok. Big Date (buyuk veri); temel anlamda 3V Volume (hacim), Velocity (hız), Variety (cesitlilik) den olusuyor. Baz kaynaklarda 6V anlayisi vardir. Hacim (Volume), Hız (Velocity), Çeşitlilik (Variety), Değer, Önem (Value), Doğruluk, Gerçeklik (Veracity) Değişkenlik, Kararsızlık (Variability)
Hız (Velocity); Hizla degisim gosteren ve hizla akan bir veriye, yapiya sahip olmalidir. Facebook gibi sürekli akan veriye sahip olmalıdır.
Çeşitlilik (Variety); Video, fotograf, metin, ses dosyalari, sayisal dokumanlar gibi cesitlilige sahip olmalıdır.
Değişkenlik, Kararsızlık (Variability); Verilerin sabit olmamasi, degisken olmasi, dagilim gostermesi gerekir.
Veri bilimi
Veri bilimi çok yaygın kullanım alanlarına sahiptir. Bunlardan başlıcaları; Suç önleme, trafik yoğunluğu ile mücadele, kurumları yönetme, hizmet sürekliliği sağlama, kayıpları azaltarak üretim faaliyetlerini düzenleme, enerji üretimi, enerji dağıtımı, enerji iletimi, gerçek zamanlı veri analizleri, başarısız öğrenci tespiti ve başarısızlık nedenleri, hasta kayıtları, tedavi planları, müşteri ilişkileri yönetimi, pazarlama araştırmaları…
Veri bilimci
Veri bilimci ise, verileri toplayan, yeni veri toplama yöntemleri geliştiren, verileri işleyen gerekli analiz yöntemlerini uygulayan, yeni analiz metodolojisi geliştiren, verileri görselleştiren, verileri bilgiye dönüştüren teknolojileri kullanan ve yeni teknolojiler geliştiren, verileri raporlayan YBS (Yönetim Bilişim Sistemleri), KDS (Karar Destek Sistemleri), Yapay Zeka gibi sistemler geliştiren kişilere verilen unvandır.
Not: Tanımlardan soru gelir.
Bilgi Piramidi
Bilgelik (Wisdom)
Anlayış (Understanding)
Tecrübe (Knowledge) – Tecrubemiz bilginin ustune eklenir. Buna tecrube-i bilgi, Üst bilgi, Knowledge denir.
Bilgi (Information) – Veriyi belli basli islemlere sokarak Bilgi elde edilir.
Veri (Data) – Elde ettigimiz her turlu deger Veridir.
Yöneticinin daha rahat karar verebilmesi, veriye dayali karar verebilmesi, analitik dusunebilmesi, zaman maliyetini azaltmasi uzerine kurulu bir uzmanlik alanidır. YBS, KDS ve Yapay Zeka bilgi piramidini taban kabul eder. Bilgi piramidinin ustune sistem insaa edilir.
Veriden Bilgi Keşfi
Teoride veri madenciliği bilgi keşfi işleminin bir parçasıdır. Pratikte veri madenciliği ve veriden bilgi keşfi aynı anlamda kullanılır.
Veri -> Veri Seçimi (Hedef veri) -> Ön İşleme -> Dönüştürme (Dönüştürülmüş veri) -> Veri Madenciliği (Örüntüler) -> Değelendirme -> BİLGİ
Ön İşleme (Ön işlenmiş veri); Veri butunlestirme, temizleme, azaltma, artrma, katogorilendirme surekli hale getirme işlemleri.
Veri Madenciliği (Örüntüler); Yontemleri %95-99 oranında klasik istatistik yontemlere benzer. Az oranda veri madenciligine has yontemlerdir.
Bu sureclerinin tamamina veri madenciligi denilebiliyor. Bu ders kapsaminda bir problemi cozmek istedigimizde bu veri kullanılıyor.
Not: Bilgi piramidi ve Veriden bilgi keşfinden soru gelir.
Değişken
Bir durumdan diğerine, gözlemden gözleme farklılık gösteren özelliklere “değişken” adı verilir.
Değişkenin belli özelliklerine karşı getirilen sayı ve sembollere ise “değişkenin değeri” adı verilmektedir.
Değişken Türleri
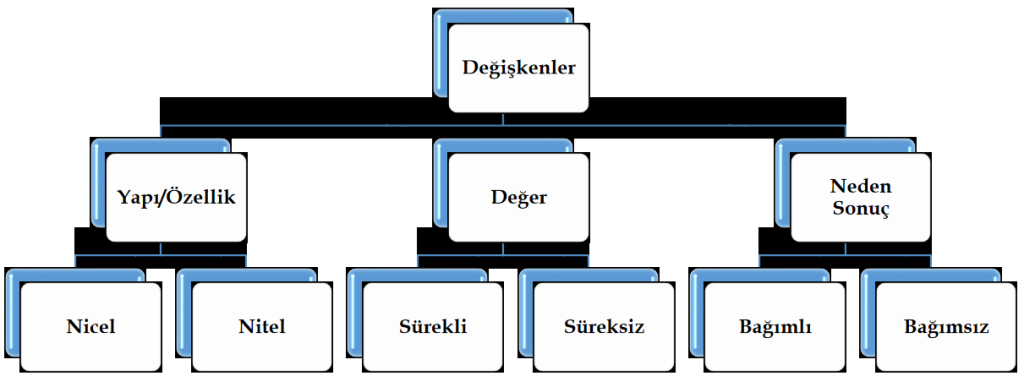
Nicel; Negatif, pozitif, ondalik, tam sayi gibi sayisal deger aliyorsa nicel degisken denir.
Nitel; Toplama cikarma gibi islemler yapilamayan, yorum yapliabilen, sayisal olmayan degiskenlerdir.
Sürekli Değişken; Kan degeri gibi, 1 ile 2 arasindaki degerler gibi sonsuz deger alabiliyorsa surekli degerdir. Tanımlı olduğu aralıkta tüm değerleri (sonsuz sayıda) alabilen değişkenlerdir. Örnek: Bir spor kulübündeki futbolcuların ağırlıkları gibi. Öğrenci notlarının ortalaması, standart sapması gibi.
Süreksiz-Kesikli Değişken; Yaş gibi belli sayida deger alabiliyorsa buna süreksiz–kesikli-deger denir. Tanımlı olduğu aralıkta sadece tam sayı değerleri alabilen değişkenlerdir. Örnek: Bir marketten gün içerisinde alışveriş yapan müşteri sayısı gibi.
Bağımlı; Baska bir degiskenin, uzerinde etkisi varsa bagimli degiskendir. Ders calisma suresinin basariyi etkilemesi gibi.
Bağımsız; Baska bir degiskenin, uzerinde etkisi yoksa bagimsiz degiskendir. Ders calisma suresini belirlemesi gibi.
Kategorik Değişken: Ölçüm veya sayımla ifade edilemeyen değişkenlerdir. Kodlanarak sayısal hale dönüştürülebildikleri için Kesikli değişkenlerin özel bir türü olarak düşünülebilir. Örnek: Cinsiyet, meslek, eğitim düzeyi…
Not: Yukarıdaki tanımlardan soru gelir.
Ölçek Nedir?
Ölçme faaliyetlerinin yerine getirilebilmesi için kullanılması gereken araçlar bütününe ölçek adı verilir.
İstatistikte kullanılan veriler sayı ile ifade edilmesi gerekmektedir. Bu sayıların nasıl ifade edileceği ölçme kavramı ile belirlenir.
Ölçek Türleri
Sınıflama (Nominal): Ortak özelliklere göre alt gruplara ayrılma (eşit, eşit değil). Cinsiyet, lise türü vb. En dusuk, en gucsuz seviyedki olcek turudur. Snflarin birbirine ustunlugu yoktur. Meslek gruplari gibi.
Sıralama (Ordinal): Ölçme sonuçlarını sıralayabilme (eşit, eşit değil, büyük, küçük). Boy sırası, rütbe vb. Biraz daha guclu olan olcektir. Arada bir rutbelendirme siralamasi varsa buna Ordinal olcek diyoruz. Bundan sonraki her turlu deger olarak degendirilir.
Aralık (Interval): Ölçme birimleri arasındaki farklar eşit (eşit, eşit değil, büyük, küçük, aralıklar eşit). Sıfır başlangıç noktası keyfi. Standart puanlar, sıcaklık miktarı (santigrat
derece). Sıcaklık ölçmede sıfır derece sicakligin yok oldugu anlamına gelmez. Sıcakliğin bir seviyesini belirtir.
Oran (Ratio): Sıfır başlangıç noktası mutlak ve yokluğu gösterir (eşit, eşit değil, büyük, küçük, aralıklar eşit, katsal ilişkiler). Ağırlık (kg), nüfus, çocuk sayısı vb. Raito da sifir mutlak ve yoklugu gosterir.
Dağılımlar
Araştırmacı tarafından gözlenerek ya da kaydedilerek elde edilen işlenmemiş sayılar yığını ham veriler olarak adlandırılır. Ham veri düzenlenmemiş verilerdir. Toplanan bu verilerin düzenlenmesinde kullanılan en basit yol frekans tablosu oluşturmaktır.
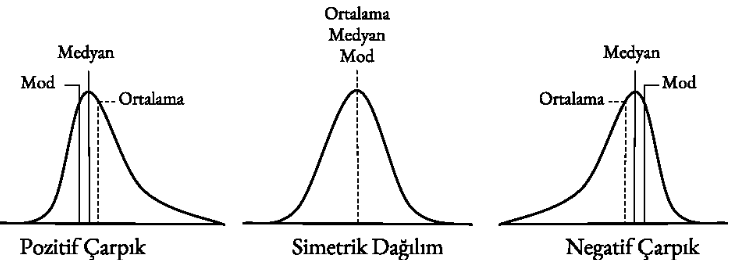
Pozitif Çarpık; Medyan ve Mod degerleri Ortalamadan daha kucuk ise buna Pozitif Carpik yada Saga Carpik deniyor.
Simetrik Dağılım; Ortalama, Medyan ve Mod degerleri birbirine esit ise buna Simetrik Dagilim deniyor.
Negatif Çarpık; Medyan ve Mod degerleri Ortalamadan daha buyuk ise ise buna Negatif Carpik yada Sola Carpik deniyor.
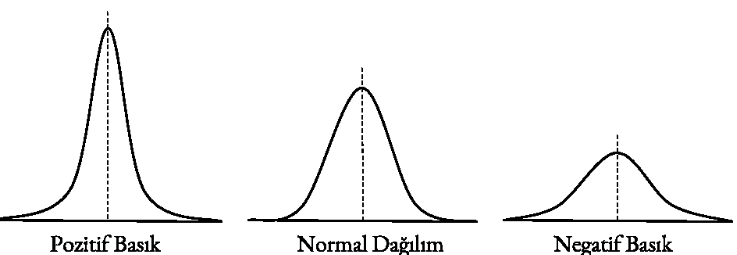
Pozitif Basık; Veriler, orta noktaya yakin, tepe noktasina ciddi yigilma varsa buraya Pozitif Basik diyoruz.
Normal Dağılım; Degerler Simetrik Yapiya benzer basik bir yapiya sahip olursa buna Normal Dagilim denir.
Negatif Basık; Veriler birbirine cok yakin degerler aliyorsa Negatif basik diyoruz.
Bu dagilimlar, arastrmada genelleme yaparken cok onemli bilgiler verir. Yapilan arastrma sonuclari Simetrik dagilim ve ya Normal Dagilima cok yakin ise genelleme yapilabilir.
Merkezi Eğilim Ölçüleri
Aritmetik Ortalama: Gözlemlerin toplamının gözlem sayısına bölünmesi (oranı).
Medyan (Ortanca): Veriler küçükten büyüğe sıralandığında en ortada kalan terimin değeridir.
Mod (Tepe Değer): Frekansı en çok olan (küme içinde en çok tekrarlanan) veridir.
Çeyreklikler (Q1, Q2, Q3): Betimsel istatistikte çeyrekler açıklığı sıralanmış bir very dizisinin orta yarısını (%50sini) kapsayan ve üçüncü dörtte birlik ve birinci dörtte birlik
aralığını veya farkını (yani Q3 – Q1) gösteren bir istatistiksel yayılma ölçüsüdür.
Q2 degeri Medyan a esittir. Elimizdeki verileri siraladigimizda tam ortadaki deger Medyan yani Q2 degerini verecektir. iki kumeye boldugumuz degerlerin ilk kumesini, tekrar iki kümeye boldugumuzde ilk kumenin tam ortasindaki deger Q1 degerini yani ilk kumenin medyan degeri bulunur. ikinci kumenin tam ortasindaki deger Q3 degerini verir. Bu ayni zamanda ikinci kumenin medyan degeridir. Q1 ile Q3 arasindaki bolum verinin yogun olarak bulundugu kume olarak belirlenir. Bu bolum Ceyreklikler Acikligi olarak adlandirilir.

MOD: (Tepe Değer-Frekans): Verilen örneğin mod değeri 1 olarak bulunur.
5, 6, 9, 1, 2, 8, 9, 3, 3, 1, 4 şeklinde verilmiş örneğin modu? 1,3,9 olur.
11, 13, 14, 10, 12, 15, 16, 18 şeklinde verilmiş örneğin modu? Bu örneğin Mod değeri yoktur. Frekans degeri 1 olan veriler gozardi edilir.
Not: Bazi istatistik programlari mod degerleri birden cok ise en kucugunu verebilir, aciklama yazar. Ozel bir calisma yok ise butun Mod degerleri raporlanmalidir.

MEDYAN: (Ortanca Değer): Verilen örneğin medyan değeri 4 olarak bulunur.
5, 6, 9, 1, 2, 8, 9, 3, 3, 1, 4 şeklinde verilmiş örneğin medyan değeri? 4 olur.
11, 13, 14, 11, 12, 15, 16, 18 şeklinde verilmiş örneğin medyan değeri? 13,5 olur.

𝑸𝟏: %25’lik veriyi temsil eder,
𝑸𝟐: %50’lik veriyi temsil eder(medyan),
𝑸𝟑: %75’lik veriyi temsil eder.
Çeyreklikler Acikligi ya da Çeyreklikler Araligi => Q3 – Q1 => 6,5 – 2 = 4,5 bulunur. Ceyreklikler Acikligi Tanimlayici istatistikte kullanilir.

Merkezi Dağılım (Yayılım) Ölçüleri
Ranj (Range): Bir ölçümün ranjı, ölçümlerin en büyüğü ile en küçüğü arasındaki farktır. Olcumu yapilan uzayin genisligini gosterir. Yukarıdaki örneğin Ranjını hesaplarsak; En büyük değer (maks) – en küçük değer (min) => Örnek veri setinin açıklığı: 9-1 = 8 bulunur.
Standart Sapma: Bir veri grubunda verilerin aritmetik ortalamadan ne kadar uzaklaştığının ölçüsüdür. Verilerin dagilimi aritmetik ortalamadan uzaklastikca standart sapma yukselir.
Varyans: Standart sapmanın karesidir. Hesaplamasi: Standart sapma hesaplar gibi hesaplanr. Varyansin Standart sapmadan farki cikan sonucun karesi alinir.
Çeyreklikler Açıklığı: 𝑄3 − 𝑄1
Q1, Q2 ve Q3 ü bulundugunda Merkezi Egilim bulunmus oluyor. Q3 ile Q1 farki bulundugunda Merkezi Dagilim bulunmus oluyor.
Varyasyon Katsayısı: Standart sapma dağılımın yaygınlığını gösteren bir ölçüdür. Standart sapmanin ortalamaya olan orani
Çarpıklık Katsayısı (Skewness): Bir dağılımda ortalama ve ortanca ayrı noktalarda ise dağılım çarpıktır.
Basıklık Katsayısı (Kurtosis): Dağılımın genişliğini yorumlamada kullanılır.

Standart sapma hesaplaması: Aritmetik ortalamadan ( ) 1.gozlemin ( ) degeri cikariliyor, karesi aliniyor. Bu şekilde sırası ile bütün gözlemlerin aritmetik ortalama ile gözlem farkinin karesi alındıktan sonra hepsi toplaniyor. Gozlem sayısı (n – 1) e bolundukten sonra (bu bulunan varyans) karekökü aliniyor.
Standart sapma hesaplaması: Aritmetik ortalamadan 1. gözlem değeri çıkarılır, karesi alınır. Gözlemlerin hepsi için bu işlem yapılır. Çıkan sonuçlar toplanır. Toplam sonucu, gözlem sayısına bölünür. (örneklem gözlemler ise gözlem sayısının 1 eksiğine bölünür). Çıkan sonucun karekökü alınır. Karakökünü almazsan varyansı bulmuş oluyorsun.
Çeyreklikler Açıklığı

Çeyrekler açıklığı sıralanmış bir veri dizisinin orta yarısını (%50 sini) kapsayan ve üçüncü çeyrek ve birinci çeyrek aralığını veya farkını (yani Q3 – Q1) gösteren bir istatistiksel yayılma ölçüsüdür.
Birinci çeyreklik sıralanmış veri dizisinin ilk %25 inden büyük ve üçüncü çeyreklik sıralanmış veri dizisinin %25 inden daha küçük olduğu için, bu iki çeyreklik arasında kalan veri yüzdesi %50’dir. Çeyrekler açıklığı ölçüm birimi veri ölçüm birimi ile aynıdır.
Varyasyon Katsayısı

Moment Çarpıklık (skewness) Katsayısı: (3. merkezi moment)
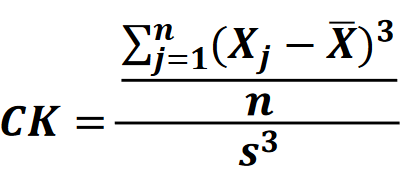
Bir reel değerli rassal değişkenin olasılık dağılımının simetrik olamayışının ölçülmesidir.
CK > 0 → Sağa çarpık
CK = 0 → Normal dağılım
CK < 0 → Sola çarpık
Mod Çarpıklık (skewness) Katsayısı:
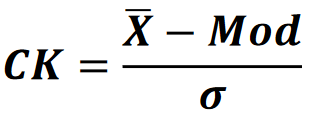
Bir reel değerli rassal değişkenin olasılık dağılımının simetrik olamayışının ölçülmesidir.
CK > 0 → Sağa çarpık. Sıfırdan bariz şekilde büyük ise.
CK = 0 → Normal dağılım. Sıfıra eşit yada çok yakın ise.
CK < 0 → Sola çarpık. Sıfırdan bariz şekilde küçük ise.
Medyan Çarpıklık (skewness) Katsayısı:
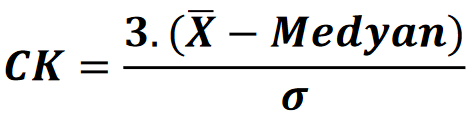
Bir reel değerli rassal değişkenin olasılık dağılımının simetrik olamayışının ölçülmesidir. 3 katsayısı gözardı edilebilir.
CK > 0 → Sağa çarpık. Veya ) değeri, sıfırdan büyük ise Sağa çarpık,
CK = 0 → Normal dağılım. Veya ) değeri, sıfıra eşit ise Normal dağılım,
CK < 0 → Sola çarpık. Veya ) değeri, sıfırdan küçük ise Sola çarpık denebilir.
Basıklık (kurtosis) Katsayısı: (4. merkezi moment):
Formüle bazen -3 eklenerek sonucun çarpıklık gibi yorumlanması sağlanmaktadır.
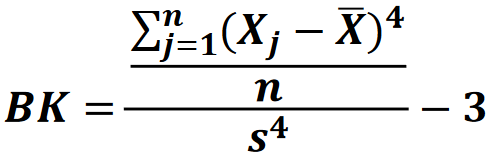
Buradaki -3 ün anlamı, 3’ten önceki bölüm hesaplanır. Çıkan sonuç 3’e göre yorumlanır. Ya da çıkan sonuç 3 azaltılarak aşağıdaki gibi sıfıra göre yorumlanır.
Basıklık kavramı bir reel değerli rassal değişken için olasılık dağılımının, grafik gösteriminden tanımlanarak ortaya çıkarılan bir kavram olan, sivriliği veya basıklığı
özelliğinin ölçümüdür.
BK > 0 → Daha sivri
BK = 0 → Normal dağılım
BK < 0 → Daha basık
HAFTA 3: Veri Kaynaklari
Bilimsel araştırmalarda değişkenlere dair veri toplamanın iki kaynağı bulunmaktadır. Bunlar;
- İkincil Veri Kaynağı
- Birincil Veri Kaynağı
İkincil Veri Kaynağı
Araştırmacılar, araştırma problemlerine cevap ararken genellikle kendi verileri ile çalışmak eğilimindedirler. Çünkü, farklı amaçlarla daha önceden derlenmiş bulunan veri setlerinden ne şekilde faydalanılacağı konusunda genellikle bilgi ya da tecrübe sahibi değildirler. Bu tür “daha önceden derlenmiş” verilere ikincil veri denir. Doğrudan kendimiz elde etmediğimiz, kendimizin toplamadığı verilere İKİNCİL VERİ denir.
Bir konuda araştırma yapılacak ise tekrara düşmemek için konu ile ilgili önce ikincil verilere bakılır. İkincil veriler mevcutsa birincil veri toplamak, hem zaman ve kaynak israfına neden olmakta hem de yeterli kaynak taraması yapılmadığı anlamına gelmektedir.
Resmi ve resmi olmayan pek çok kurum, sürekli olarak ekonomik, toplumsal, siyasi vb. alanlarda çok farklı konular üzerinde ayrıntılı veriler toplamaktadır. Ülke Merkez Bankaları, Ekonomi Bakanlığı, TÜİK, İTO, İSO, Dünya Bankası, IMF gibi kuruluşlar, sendikalar, meslek odaları, düzenli olarak topladıkları verileri kamunun hizmetine sunmaktadır. Bu verilerin çoğu bilgisayar ortamında hazırlanmıştır ve internet aracılığıyla ulaşılabilmektedir.
İkincil veriler hem nitel hem nicel araştırmalarda; hem betimleme hem de açıklama amaçlarıyla kullanılabilirler. Bazı ikincil veriler tamamen ham very iken (toplantı tutanakları), bazıları işlenmiş verilerdir (şirket bilançoları).
İkincil verinin avantajları:
- İkincil verilerin en önemli üstünlükleri, araştırmanın zaman ve maliyet kısıtına uygun olmasıdır.
- Periyodik araştırmalara imkan sağlar. İkincil verilerle 10, 25 hatta 50 yıllık dönemler için analiz yapmak mümkündür. Birincil veriler ile bunu yapmak mümkün değildir.
- Ülke, bölge vb. temelli karşılaştırma yapma olanağı sağlar.
İkincil verinin dezavantajları:
- İkincil veriler araştırma sorularına cevap vermeyebilirler. Çünkü, araştırmacının amacından farklı amaçlarla toplanmış olabilirler.
- Bazı ulusal ya da uluslararası danışmanlık şirketleri, kamuoyu araştırma kuruluşları vb. derledikleri verileri araştırmacının sahip olduğu bütçeyi aşacak şekilde yüksek fiyata satabilmektedirler. Bu durumda ikincil kaynaklar seçenek olmaktan çıkmaktadır.
- Araştırmacı çalışmasını bir kuramı sınamak ya da bir olguyu açıklamak üzere tasarlamış olabilir. Bu iş için, çok sayıda değişkene ilişkin bilgiler içeren geniş bir veri setine ihtiyaç duyar. Fakat bu konudaki ikincil veriler araştırmacıya gereken ölçüde geniş hazırlanmamış olabilir. Bu durumda araştırmacı, araştırmasını sınırlandırmak zorunda kalır.
Birincil Veri Kaynağı:
Araştırmacının çalışması için ihtiyaç duyduğu verileri, değişik araçlarla kendisinin toplaması ile elde edilen verilere birincil veri denir. Birincil verilerin toplanmasında 4 tür yöntem vardır. Bunlar:
• Anket: Gözlem; Bir sınıfta, online bir ortamda verilen cevaplarla, yapılan konuşmalar da olabilir. Yine bir işyerinin, ortamın belli bir süre gözetim altında tutulması ile olabilir.
• Mülakat: Deneysel Yol; bir işeyrinde ışığın kesilmesi, üretime, performansa nasıl etki ettiği deneyerek belirlenmesi gibi.
Not: Veri kaynağı türlerinden soru gelir.
Ölçek Türleri
Değişkenlerin ölçülmesinde kullanılan 4 farklı duyarlılık düzeyi vardır. Bu düzeyler;
➢Sınıflama (Nominal) ölçme düzeyi
➢Sıralama (Ordinal) ölçme düzeyi
➢Eşit aralıklı (Interval) ölçme düzeyi
➢Oranlama (Ratio) ölçme düzeyi
➢Scale (Interval + Ratio)
Not: Soru gelebilir.
Veri Dönüşümleri
Kesikli veriyi süreki very haline dönştürme:
Bir sınıftaki öğrencilerin ayrı ayrı yaşları kesikli veridir. Yani tamsayıdır. Bu öğrencilerin yaşlarının aritmetik ortalaması alınırsa sürekli veriye dönüştürülmüş olur.
Sürekli veriyi kesikli veri haline dönüştürme:
Ayrıklaştırma (discretization veya binning) nümerik verilerin kategorik karşılıklarına dönüştürülmesi işlemine verilen addır.
Yaş değişkeninin değerlerini aralıklara gruplama işlemi buna bir örnek olarak verilebilir.
Bu yöntem aykırı gözlemlerin tespitini, geçersiz veya eksik numerik değerlerin tespitini kolaylaştırır.
Eşit Genişlikli Kova Metodu (Binning Method):
Bu gruplama yönteminde sürekli bir değişken eşit genişlikteki n aralığa bölünür. Eğer bir değişkenin aldığı en küçük değer ve en büyük değer sırasıyla A ve B ise ve n aralığa bölünmek isteniyorsa genişlik şu formülle hesaplanır:
𝑤 = (𝐵 – 𝐴) / 𝑛
w -> aralık genişliği, B -> en büyük değer, A -> en küçük değer, n -> Kategori (istene grup sayısı, aralık sayısı) sayısı.
Eşit genişlikte gruplama yöntemi bazı avantajlara ve dezavantajlara sahiptir. Fakat diğer yandan denetlenmeyen (unsupervised) bir yöntem olması, n sayısının ne kadar olması gerektiğinin tam olarak bilinememesi ve aykırı gözlemlere son derece hassas olması dezavantajlarıdır.
Örnek:
Yaşları 18 ile 69 arasında değişen insanları, genç, orta ve yaşlı diye 3 gruba gruplandırmak istersek;
bulunur. En küçük yaşa 17 eklenir. genç grubu bulunur. Genç Grubu: 18 ile 34 yaşları
İlk grubun en bitiş sayısına 17 eklenir. orta yaş grubu bulunur. Orta Yaş Grubu: 35 ile 51 yaşları
İkinci grubun bitiş yaşına 17 eklenir. bulunur. Yaşlı Grubu: 52 ile 69 yaşları diye gruplandırılır.
Eşit Derinlikli Kova Metodu (Binning Method):
Bu yöntemde değerler yaklaşık olarak eşit sayıda eleman içeren n aralığa bölünür. Kümelenmeyi önlediği için ve pratikte “neredeyse eşit” yükseklikte gruplama daha sezgisel kesim noktaları verdiğinden özellikle tercih edilir.
Bu yöntemde aynı değerlere sahip verilerin aynı kümeye dahil olması gereklidir. Dolayısı ile kümelerin frekanslarının (eleman sayılarının) eşitliği bozulabilir.
Örnek:
10, 11, 11, 12, 12, 12, 13, 14, 15, 16, 17, 18, 19, 20, 22
𝑤 = (𝐵 – 𝐴) / n => 𝑛 = (22 – 10) / 3 => n = 4 bulunur.
1. Grup -> 10-13 — 10, 11, 11, 12, 12, 12, 13
2. Grup -> 14-17 — 14, 15, 16, 17
3. Grup -> 18-22 — 18, 19, 20, 22
Örnek:
10, 11, 11, 12, 12, 12, 13, 14, 15, 16, 17, 18, 19, 20, 22
𝑤 = n / 3 => w = 15 / 3 = 5 bulunur. w ->Grup genişliği, n -> Veri sayısı, Buradaki 3 grup sayısı.
1. Grup -> 10,11,11,12,12,12 -> Aynı büyüklükteki değerler aynı gruba toplanır.
2. Grup -> 13, 14, 15, 16
3. Grup -> 17, 18, 19, 20, 22 -> 17, ikinci gruba da yazılsa 3. gruba da yazılsa doğrudur. önemli olan her grubun 5 veriye yakın veriye sahip olmasıdır.
Bu şekilde de gruplandırılabilir;
1. Grup -> 10, 11, 11, 12, 12, 12
2. Grup -> 13, 14, 15, 16, 17
3. Grup -> 18, 19, 20, 22
Not: Binning Metodundan soru gelir.
HAFTA 4: Aykiri Verilerin Düzenlenmesi
Aykırı (Sapan) değerler; ölçüm hataları, kayıt hataları, veri dönüştürme hataları gibi nedenlerle olarak ortaya çıkabilmektedirler.
Ayrıca verilerin tanımladığı gerçek problemi yansıtmayacak (temsil edemeyecek) aykırı değerler bazen çok düşük olasılıkla gerçekleşmesi muhtemel olayların veri kümesine eklenmesinden de kaynaklanabilir.
Sağlıklı bir analiz yapmak, doğru çıkarımda bulunabilmek, doğru bilgi edinebilmek için aykırı verilerin çıkarılması gerekir.
Veriler anket vb. yöntemlerle toplanırken okuma veya yazma hatası gibi gerekçelerle verinin hatalı girilmesi olabilir.
Ölçümleri bilgisayar ortamına taşırken gerçek değeri 4 olan veri 34 olarak yazılmış olabilir.
Ölçüm cihazının (sensör vb….) etkilenmesi, arızalanması gibi nedenlerle gerçek değeri 33 olan bir verinin değerini 113 olarak ölçülmüş olabilir.
Her 1000 örnekten yalnızca 1’inde gerçekleşen bir durumu veri kümesi içine dahil ederek, genelleme yapmaya çalışmak gibi nedenler…
Aykırı verilerin düzenlenmesi için öncelikle tespit edilmesi gerekir!
Aykırı Verilerin Tespitinde Kullanılan Yöntemler
İstatistiksel Yöntemler:
- 1) Grafik Yöntemler
- 2) Z – Puanları
- 3) Q yöntemi (Tukey’s Yöntemi)
- 4) Ortalama-Medyan İlişkisi
- 5) Diğer Yöntemler (Chauvenet Yöntemi, Dixon-Thompson Testi, Rosner Testi, Grubbs Testi, …)
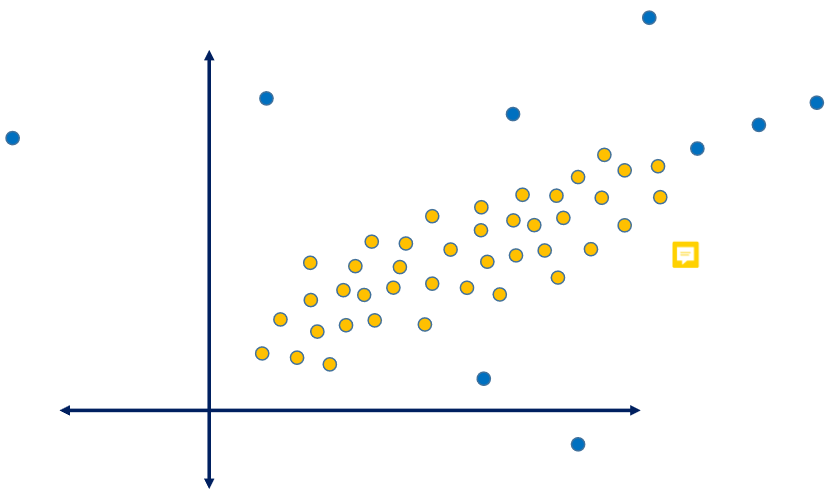
1) Grafik yöntemler – Görselleştirerek aykırı veri tespiti:
Scater Plate (saçılım) yöntemi
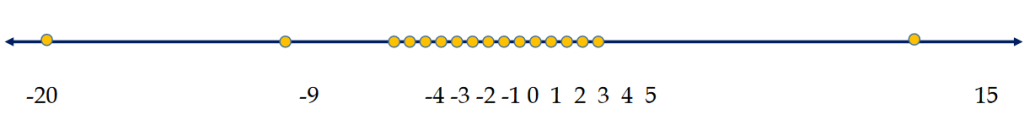
Sarı verilerin alınması sağlıklı olur. sağdaki üç veriyi almak araştırmayı yapan kişinin uzmanlığına bağlı.
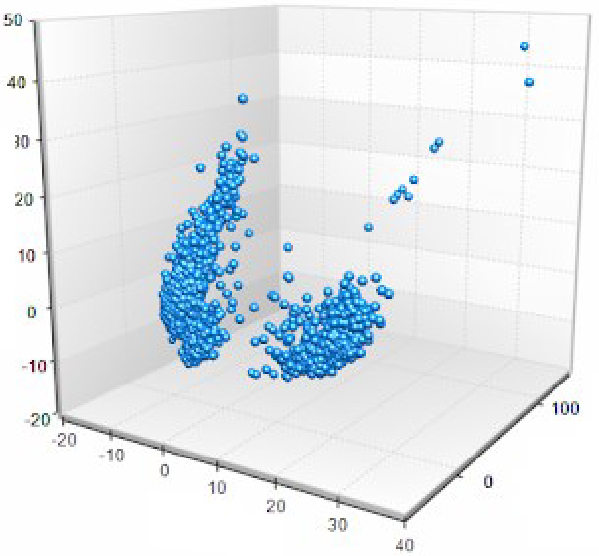
3 boyutlu veri setinde aykırı değerler…
iki grup baz alınır. iki grup arasında kalan veriler alınmaz. İki grup arasındaki veriler. kararsız kalan verilerdir. Çıkarım yapmayı çok zorlaştırır.
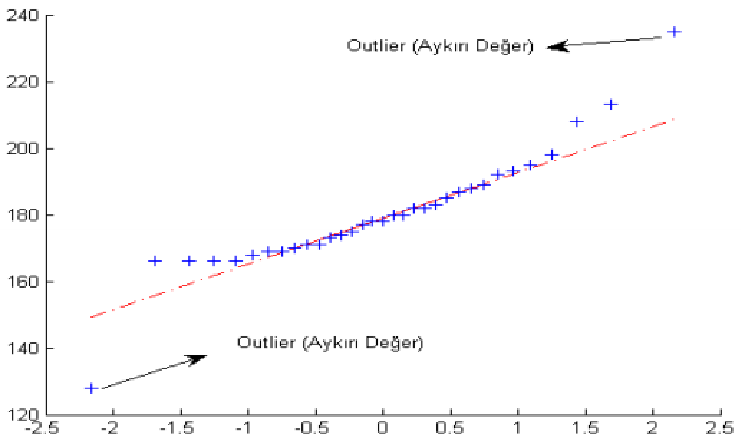
Görselleştirerek aykırı veri tespiti: Q-Q Grafiği Tekniği
Standart normal dağılıma karşılık gerçek veri kümesi elemanları grafiğinin dağılımı incelenir.
Görselleştirerek aykırı veri tespiti: Histogram Tekniği
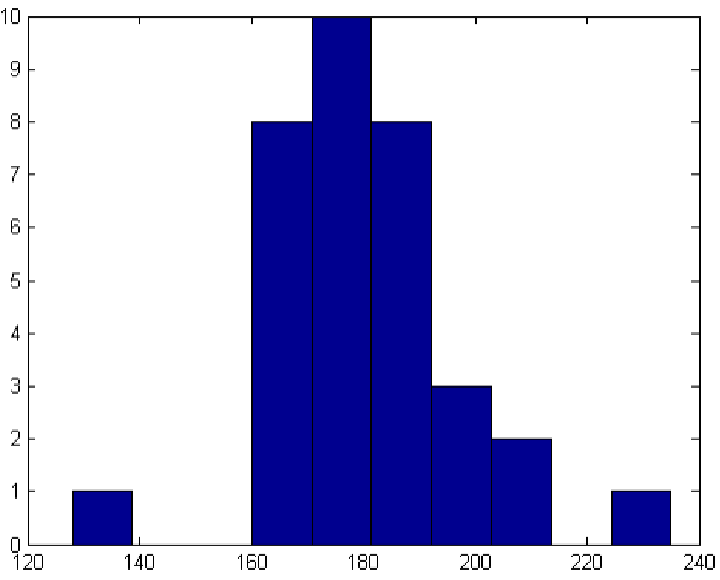
Verilerin sıklıkları (frekansları) doğrultusunda çizilen grafiğe göre aykırı değer tespit edilir.
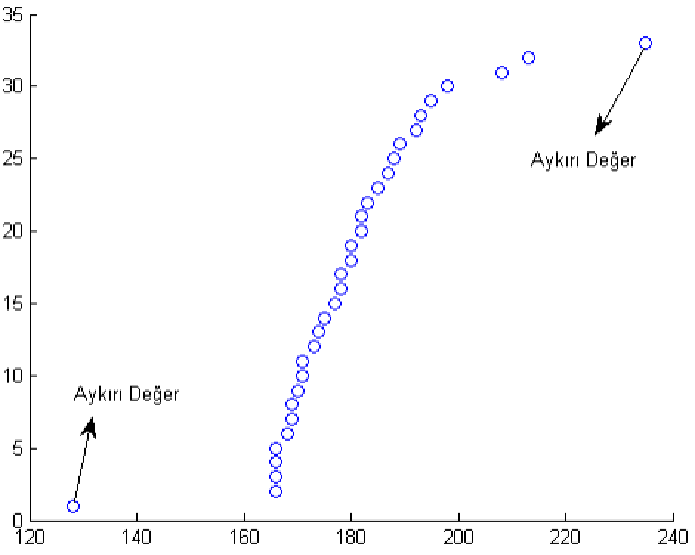
Görselleştirerek aykırı veri tespiti: Akış Dizisi Tekniği
Grafiğin X eksenine gözlem değerleri Y eksenine ise bu gözlem değerlerinin sıra numaraları konularak koordinat sisteminde gözlem değerleri işaretlenir. Grafiğin akışını bozan değerler aykırı değer olarak belirlenir.
Z-Puanları
𝑍 𝑝𝑢𝑎𝑛𝚤 = (𝑋 – 𝜇) / 𝜎
X -> Veri (gözlem): En sağdaki ve en soldaki değerler sırası ile denenir. Aykırı veri bulunmayana kadar denemeye devam edilir. 𝜇 -> Aritmetik ortalama. ò -> Ana kütle standart sapması.
Bir veri setinde aykırı değerleri saptama yöntemlerinden birisi “z-score” dur. Z-score verileri ölçeklendirerek, ortalaması 0 ve standart sapması 1 olacak şekilde düzenler.
Daha sonra bir değerin ortalamanın ne kadar uzağında olduğunu ölçer. Bununla birlikte, bir değerin aykırı olduğunu söylemek için, z-score için bir eşik belirlememiz gerekir, bu sayede bu eşiğin üzerindeki skorların aykırı olduğu söylenir.
Genellikle 3 veya -3 sigma eşiği kullanılır. Z-score değeri sırasıyla 3 veya -3’ten büyük veya küçükse, bu veri noktası aykırı değer olarak belirlenecektir.
Örnek:
Veriler: 4, 4, 4, 5, 6, 7, 8, 8, 8, 8, 8, 9, 10, 12, 14, 14, 14, 14, 14, 15, 17, 18, 19, 20, 21, 22, 22, 22, 23, 24, 25, 25, 26, 27, 27, 28, 28, 28, 41
Aritmetik ortalaması: Veri Toplamı / veri sayısı = 16,64
Standart Sapma: ò = 8,88
En soldaki ve en sağdaki veriler sırası ile formülde yerine konup aykırı veri olup olmadığna bakılır.
Z-score = (X – µ) / ò = (4 – 16,64) / 8,88 = -12,64 / 8,88 = – 1,42 bulunur. -3 den küçük olmadığı için 4 aykırı veri değildir.
Z-score = (X – µ) / ò = (41 – 16,64) / 8,88 = 24,36 / 8,88 = 2,74 bulunur. 3 ten büyük olmadığı için 41 aykırı veri değildir.
Görselleştirerek aykırı veri tespiti: Kutu-Grafiği (Box Plot) – Tukey Metodu: (Q metodu) Box Plot
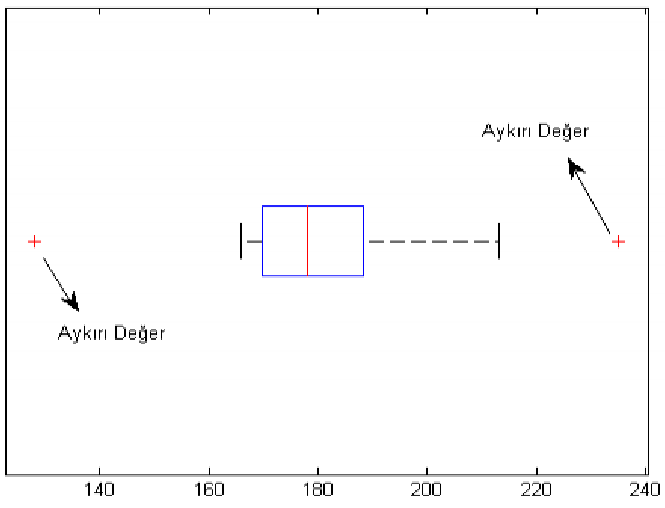
Bu yöntemde öncelikle çeyreklikler (𝑄1, 𝑄2, 𝑄3) ve çeyreklikler açıklığı 𝑑𝑞 = 𝑄3-𝑄1 bulunur. Sonrada aykırı değerin olmadığı gözlem aralığı değerlendirilir.
[𝑄1 – 1,5. 𝑑𝑞, 𝑄3 + 1,5. 𝑑𝑞]
Örnek:
Tukey Metodu (Q metodu) aykırı veri tespiti:
Veriler: 4,4,4,5,6,7,8,8,8, 8, 8,9,10,12,14,14,14,14,14,15,17,18,19,20,21,22,22,22,23,24, 25, 25, 26, 27,27, 28, 28, 28, 41
| DEĞERLER | FREKANS | |||
| 4 | 3 | 12 | ||
| 5 | 1 | 5 | ||
| 6 | 1 | 6 | ||
| 7 | 1 | 7 | ||
| Q1 | 8 | 5 | 40 | |
| 9 | 1 | 9 | ||
| 10 | 1 | 10 | ||
| 12 | 1 | 12 | ||
| 14 | 5 | 70 | ||
| Q2(Medyan) | 15 | 1 | 15 | |
| 17 | 1 | 17 | ||
| 18 | 1 | 18 | ||
| 19 | 1 | 19 | ||
| 20 | 1 | 20 | ||
| 21 | 1 | 21 | ||
| 22 | 3 | 66 | ||
| 23 | 1 | 23 | ||
| Q3 | 24 | 1 | 24 | |
| 25 | 2 | 50 | ||
| 26 | 1 | 26 | ||
| 27 | 2 | 54 | ||
| 28 | 3 | 84 | ||
| 41 | 1 | 41 | ||
| 39 VERİ |
Toplam 39 veri. Q2 = 15, Q1 = 8, Q3 = 24, Çeyreklikler açıklığı: 𝑑𝑞 = 𝑄3 – 𝑄1 = 24 – 8 => 𝑑𝑞 = 16 bulunur.
Aykırı-hariç tutulacak GÖZLEM ARALIĞI: [𝑄1 – 1,5 . 𝑑𝑞, 𝑄3 + 1,5 . 𝑑𝑞] => [8-1,5 . 16, 24 + 1,5 . 16] => [8 – 24, 24 + 24] => GÖZLEM ARALIĞI: [-16, 48] aralığıdır.
Not: Yukarıdaki örneğe benzer soru gelir.
Ortalama Medyan İlişkisi:
Veri setinin medyanı ve ortalaması arasında fark büyüdükçe veri setinde aykırı değer bulunma olasılığı artmaktadır. Fakat bu göreceli bir durum olduğu için risk içermektedir.
Çok tercih edilmeyen bir yöntemdir. Aykırı verilerin tespitinde (düzenlenmesinde) kullanılmaz.
Not: Aykırı veriler tespit edildiğinde bilimsel araştırmadan çıkarılır, kullanılmaz.
HAFTA 5: Veri Ön Işleme
Veri ön işleme, ham verilerin anlaşılır bir biçime dönüştürülmesini içeren bir veri madenciliği tekniğidir.
Gerçek dünya verileri genellikle eksiktir, tutarsızdır veya belirli davranışlarda (eğilimlerde) eksiktir. Bu sebeple muhtemelen çok sayıda hata içerir. Veri ön işleme, bu tür sorunları çözmek için kanıtlanmış bir yöntemdir.
İstatistik biraz daha yorumlama bilimidir. Yorumlama yaparken matematiksel yöntemler kullanarak genelleme yapabiliyoruz. Doğruya yakın verilere ulaşabiliyoruz.
İstatistikte %5 hata kabul edilebilir bir hatadır. Ama insan hayatı söz konusu olduğunda %1 hata ancak kabul edilir.
Örnek Veri Seti: Eksik Veri
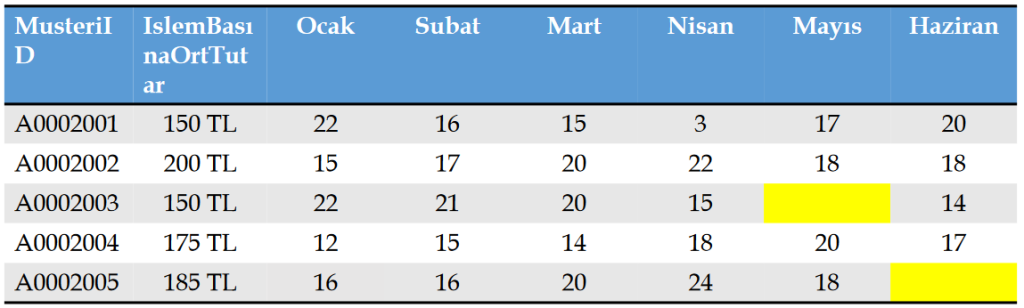
Eksik/Kayip veri:
1) Veri toplama hatası kaynaklı
2) Veri girişi hatası kaynaklı
3) Sensör ve diğer teknolojilerdeki hata kaynaklı
Eksik ya da kayıp veri problemi, yapay zeka uygulamaları (makine öğrenmesi, istatistiksel öğrenme, zaman serisi analizleri, …), veri madenciliği uygulamaları (sınıflandırma, kümeleme, birliktelik, tahmin) veya diğer istatistiksel analizlerde sıklıkla karşılaşılan bir durumdur.
Eksik/Kayıp Veriyi Değerlendirme:
1) Silme (Deletion)
i. Satır (Raw) bazlı silme
ii. Sütun (Column) bazlı silme
iii. Eşler (Pairwise) bazlı silme
2) Doldurma (Imputation)
i. Min, Maks, Sabit, Ortalama, Medyan, Mod, … ile doldurma
ii. Regresyon ile doldurma
Araştırma yapılan konu ile ilgili uzmanlığımız yoksa ve veri madenciliği/istatistik uzmanlığımız yoksa tek çare eksik/kayıp veriyi Silme yöntemidir.
Hem veri madenciliği/istatistik uzmanlığımız hemde araştırılan konu ile ilgili bizim yada ekibimiz içinde uzmanlığı olan varsa Doldurma yöntemi seçilebiliyor.
Temel Istatistik Işlemler
Örnek veri: Düzenlenmiş Örnek veri:
A: 1, 5, -2, 3, 0, 7, 2, 1, 2 A: -2, 0, 1, 1, 2, 2, 3, 5, 7
B: 2, 11, 5, 0, 2, 5, 3, 1, 3 B: 0, 1, 2, 2, 3, 3, 5, 5, 11
C: -1.5, 5, 7, 11.2, 3, 6, 4, 2 C: -1.5, 2, 3, 4, 5, 6, 7, 11.2
D: 1, 2, 3, 2.5, 5, 6, 6.5, 3, 2 D: 1, 2, 2, 2.5, 3, 3, 5, 6, 6.5
Minimum Fonksiyonu: min() ve Maksimum Fonksiyonu: maks()
min(A)= -2 maks(A)= 7 min(B)= 0 maks(B)= 11 min(C)= -1.5 maks(C)= 11.2 min(D)= 1 maks(D)= 6.5
Ortalama Fonksiyonu: ort(), Medyan Fonksiyonu: med(), Mod Fonksiyonu: mod()
ort(A): 2.11 med(A): 2 mod(A): 1 ve 2
ort(B): 3.56 med(B): 3 mod(B): 2, 3 ve 5
ort(C): 4.5 med(C): 4.5 mod(C): NaN (Not a Number)
ort(D): 3.14 med(D): 3 mod(D): 2 ve 3
Not: Bazı programlar Birden fazla mod (Frekans) varsa sadece birini belirtip açıklama yazar.
1) SİLME:
Genelleme yapmak çok doğru olmasa da satırda bulunan gözlem ya da özelliklerde %25-%33’ün üzerinde eksik/kayıp veri mevcutsa bu satır çalışmadan çıkarılır. Hem veri uzmanlığı hem konu uzmanlığı mevcut olmasına rağmen bir satırdaki verinin %25 – % 33 ü üzerinde eksik ise satrıdan silinmesi gerekir.
Benzer şekilde genelleme yapmak çok doğru olmasa da sütunda bulunan gözlem ya da özelliklerde %25-%33’ün üzerinde eksik/kayıp veri mevcutsa bu sütun çalışmadan çıkarılır. Hem veri uzmanlığı hem konu uzmanlığı mevcut olmasına rağmen bir sütunaki verinin %25 – % 33 ü üzerinde eksik ise sütundan silinmesi gerekir.
Satır ve sütun silme yöntemine dahil edilebilecek değişken bazlı veri eksiltmeler bu kategoride ele alınmaktadır. Çalışmada ihtiyaç duyulmayacak değişkenlerin silinmesi olarak özetlenebilir.
2) DOLDURMA:
Eksik verinin yer aldığı satır ya da sütunda bulunan verilerin en küçüğü (minimum), en büyüğü (maksimum), değişkene özel atanan sabit bir değer, ortalama, medyan, mod gibi değişkenler ile doldurulabilir.
Veri doldurma (tamamlama) uzmanlık gerektiren bir iştir. Hatalı yapılacak bir veri doldurma işlemi, verinin kendi doğasını (yapısını) ve dağılımını değiştirebilir. Bu durum elde edilecek sonuçlarında gerçeği yansıtmayan hatalı sonuçlar elde edilmesini sağlayabilir. Dolayısıyla araştırmada konu olan problemin bir alan uzmanı tarafından değerlendirilmesi gerekmektedir. (Yani sadece veri bilimi uzmanı olmak bu süreçte yeterli olmayabilir.)
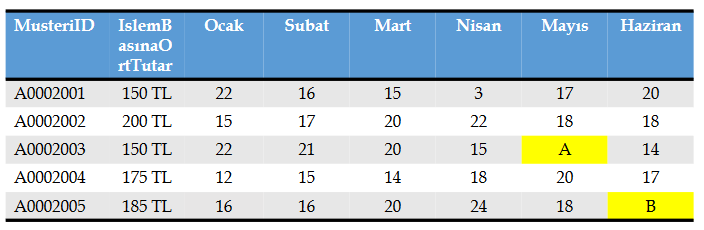
En küçük değer ile doldurma:
A hücresinin bulunduğu satırda bulunan verilerin en küçüğü 14 olduğundan A=14,
B hücresinin bulunduğu satırda bulunan verilerin en küçüğü 16 olduğundan B=16.
A hücresinin bulunduğu sütunda bulunan verilerin en küçüğü 17 olduğundan A=17,
B hücresinin bulunduğu sütunda bulunan verilerin en küçüğü 14 olduğundan B=14.
Peki hangisini kullanmalıyız? Cevap: Doldurma yapmadan analizi yapılan konu ve uzmanı doldurma seçeneğini seçmelidir.
En büyük değer ile doldurma:
A hücresinin bulunduğu satırda bulunan verilerin en büyüğü 22 olduğundan A=22,
B hücresinin bulunduğu satırda bulunan verilerin en büyüğü 24 olduğundan B=24.
A hücresinin bulunduğu sütunda bulunan verilerin en büyüğü 20 olduğundan A=20,
B hücresinin bulunduğu sütunda bulunan verilerin en büyüğü 20 olduğundan B=20.
Peki hangisini kullanmalıyız? Cevap: Doldurma yöntemi araştırması yapılan konuya ve uzmanlığa bağlıdır.
Ortalama değer ile doldurma:
A hücresinin bulunduğu satırın ortalaması 18,4 olduğundan A=18,4
B hücresinin bulunduğu satırın ortalaması 18,8 olduğundan B=18,8.
A hücresinin bulunduğu sütunun ortalaması 18,25 olduğundan A=18,25
B hücresinin bulunduğu sütunun ortalaması 17,25 olduğundan B=17,25.
Peki hangisini kullanmalıyız? Cevap: Bu sayılar insan sayısı ise küsuratlı sayılar ile doldurulmaz.
Medyan değer ile doldurma:
A hücresinin bulunduğu satırın medyanı 20 olduğundan A=20
B hücresinin bulunduğu satırın medyanı 18 olduğundan B=18.
A hücresinin bulunduğu sütunun medyanı 18 olduğundan A=18
B hücresinin bulunduğu sütunun medyanı 17,5 olduğundan B=17,5.
Peki hangisini kullanmalıyız?
Mod değer ile doldurma:
A hücresinin bulunduğu satırın modu ‘Yok’ olduğundan A=NaN
B hücresinin bulunduğu satırın modu 16 olduğundan B=16.
A hücresinin bulunduğu sütunun modu 18 olduğundan A=18
B hücresinin bulunduğu sütunun modu ‘Yok’ olduğundan B=NaN.
Peki hangisini kullanmalıyız?
Sabit değer ile doldurma:
Eksik verinin bulunduğu satır veya sütuna göre uzmanın öngörüsü doğrultusunda sabit bir değer atanır. Fakat bu işlemin çok öznel bir yaklaşım olduğu unutulmamalıdır.
Örnek: A hücresinin bulunduğu satırda giderek azalan bir veri olduğundan A hücresinin 15 değeri ile doldurulması mümkündür. B hücresinin bulunduğu satır veya sütuna bakıldığında doğrudan bir azalma ya da artış trendi gözlenemediğinden B hücresine 16 değerinin atanması mümkündür.
Peki bu atamalar ne kadar güvenilir?
Cevap: Doldurma seçeneğini seçmek; analizi yapılan konuya, konu hakkındaki uzmanlığa, yorumlamamıza bağlıdır. Tek bir cevabı yoktur.
Özet Doldurma Tablosu

HAFTA 6: Özet Veri
Veri analizinde çok sayıda gözlemle çalışmalar yapıldığında verinin eğilimini ve dağılımını anlamak büyük önem arz etmektedir.
Verinin davranışını anlamak, verinin bilgiye dönüşüm sürecinde kilit rol üstlenmektedir.
Özet Veri Raporlamasi
Frekans Analizi: Frekans sıklık anlamında kullanılan bir kelimedir.
Veri kümesi içinde hangi veriden kaç defa bulunduğu ile ilgili bilgileri özetleme yöntemidir. Ayrıca verinin görselleştirilmesi için uygulanan ilk adımdır.
Örnek:
Veriler:
1, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 8, 9, 10, 10, 10
FREKANS ANALİZİ FREKANS ANALİZ TABLOSU
| VERİ | FREKANS | % YÜZDE | KÜMÜLATİF % | ||
| 1 | 5 | 5 | %12,82 | %12,82 | |
| 2 | 3 | 6 | %7,69 | %20,51 | |
| = Mod | 3 | 10 | 30 | %25,64 | %46,15 |
| 4 | 4 | 16 | %10,26 | %56,41 | |
| 5 | 4 | 20 | %10,26 | %66,67 | |
| 6 | 4 | 24 | %10,26 | %76,93 | |
| 7 | 4 | 28 | %10,26 | %87,19 | |
| 8 | 1 | 8 | %2,56 | %89,75 | |
| 9 | 1 | 9 | %2,56 | %92,31 | |
| 10 | 3 | 30 | %7,69 | %100 | |
| TOPLAMLAR | 39 VERİ | 176 |
Aritmetik ortalama = 4,51
Frekans Analizinden
Frekans tablosundan medyan(ortanca) ve bulmak: 39 adet verinin medyan sırası 20 olur. Sütundan yukarıdan aşağıya (yada aşağıdan yukarıya farketmiyor) 20 nin dahil olduğu kümeyi bulana kadar toplayarak ilerliyoruz. 20 nin dahil olduğu kümenin yanındaki veri ve medyan değeridir. Burada Medyan (= )= 4 dür
Frekans tablosundan hesaplamak: 39 adet verinin si 20. Sıraydı. 20.sıradan geriye doğru sayıldığında 19 bulunur. Ortancası 10. sıradaki sayı olur. Frekans tablosundan üstten başlayarak toplamı 10 olan kümeyi bulana kadar toplamaya devam edilir. Frekans Toplamı 10 a denk gelen kümenin yanındaki veri olur. Burada = 3 olur.
Frekans tablosundan hesaplamak: Sondan 20 ye kadar olan sayılar 19 adettir. Ortancası sondan 10. sıradaki sayı olur. Frekans tablosundan alttan başlayarak toplamı 10 olan kümeyi bulana kadar toplamaya devam edilir. Frekans Toplamı 10 a denk gelen kümenin yanındaki veri olur. Burada olur.
Frekans tablosundan mod bulmak: Frekans sütununda en yüksek olan değerin yanındaki veri mod değeridir. Burada en yüksek frekans 10 dur. 10′ nun yanındaki veri 3 tür. Mod=3 tür.
Frekans tablosundan Aritmetik ortalamayı bulmak: Çarpımların sonuçları toplanarak frekansların toplamına (veri sayısı) bölünür. Frekans tablosundan Her Veri frekansı ile çarpılır. (1*5+2*3+3*10+4*4+5*4+6*4+7*4+8*1+9*1+10*3) / (5+3+10+4+4+4+4+1+1+3) = 4,51 bulunur
Örnek:
Veriler:
1,1,1,1,1,2,2,2,3,3,3,3,3,3,3,3,3,3,4,4,4,4,5,5,5,5,6,6,6,6,7,7,7,7,8,9,10,10,10
Frekans Analiz Tablosundan
Frekans (Mod) Yüzdelerini hesaplamak: Frekans sayısı Toplam gözlem sayısına (toplam veri sayısı) bölünür. Çıkan sonuç frekansın toplam veri içindeki % sidir.
Kümülatif yüzde hesaplamak: Frekans (Mod) yüzdeleri yukarıdan aşağıya toplanarak inilir.
Örnek:
Veriler:
1,1,1,1,1,2,2,2,3,3,3,3,3,3,3,3,3,3,4,4,4,4,5,5,5,5,6,6,6,6,7,7,7,7,8,9,10,10,10
5 Numberi Summary (5 Sayı Özeti) Veri Özet Tablosu
| Minumum | 1,000 |
| Q1 | 3,000 |
| Q2 | 4,000 |
| Q3 | 6,000 |
| Maksimum | 10,000 |
Minumum: en küçük veri
Minumum ile maksimum verilerin ortalamasını aldığımızda 5,5 ediyor. değerinin 5,5 olması beklenirdi. değeri daha düşük çıktığı (4) için verilerin ilk 50 nin (yada ilk yarının) içinde yoğunlaştığını söyleyebiliriz. İlk 50 de daha çok veri var.
değerinin de minumum ile maksimum verilerin ortalamasına göre 7-7,5 civarında olması beklenirdi. Buda gösteriyor ki veriler ilk yarı da çok var. Sol tarafta yığılma var.
Maksimum: En byük veri.
Not: Yukarıdaki özet verilerden soru gelir.
Örnek:
Veriler:
1,1,1,1,1,2,2,2,3,3,3,3,3,3,3,3,3,3,4,4,4,4,5,5,5,5,6,6,6,6,7,7,7,7,8,9,10,10,10
Toplam = 176, Ortalama = 4,51
Detaylı Veri Özet Tablosu:
| Minumum | 1,000 | Q1 | 3,000 |
| Maksimum | 10,000 | Q2 | 4,000 |
| Açıklık (Range) | 9,000 | Q3 | 6,000 |
| Standart Sapma | 2,624 | Medyan | 4,000 |
| Varyans | 6,888 | Mod | 3,000 |
Range (Açıklık) Bulmak: En büyük veri den en küçük veri çıkarılır. bulunur.
Çapraz Tablo
Kadın: 1 Erkek: 2
AA:5 BA:4 BB:3 CB:2 CC:1
Çok Memnun: 5 Memnun: 4 Kararsız: 3 Memnun değil: 2 Hiç memnun değil: 1
| Cinsiyet | Memnuiyet | Başarı Puanı |
| 1 | 3 | 3 |
| 2 | 4 | 5 |
| 1 | 5 | 4 |
| 2 | 5 | 4 |
| 2 | 4 | 4 |
| 2 | 4 | 3 |
| 1 | 3 | 5 |
| 1 | 3 | 4 |
| 2 | 1 | 2 |
| 2 | 3 | 4 |
| 2 | 4 | 2 |
| 1 | 3 | 1 |
| 2 | 2 | 1 |
| 1 | 1 | 2 |
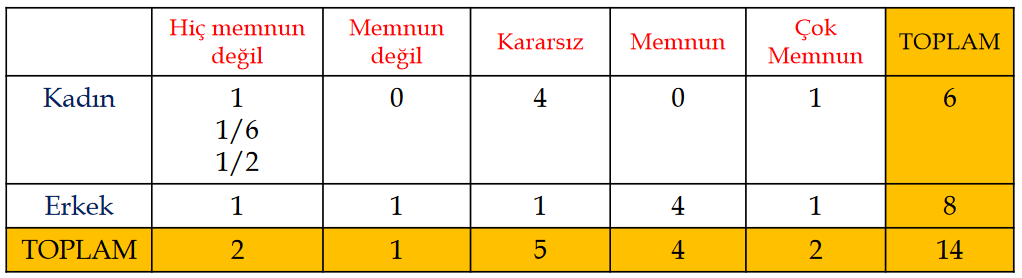

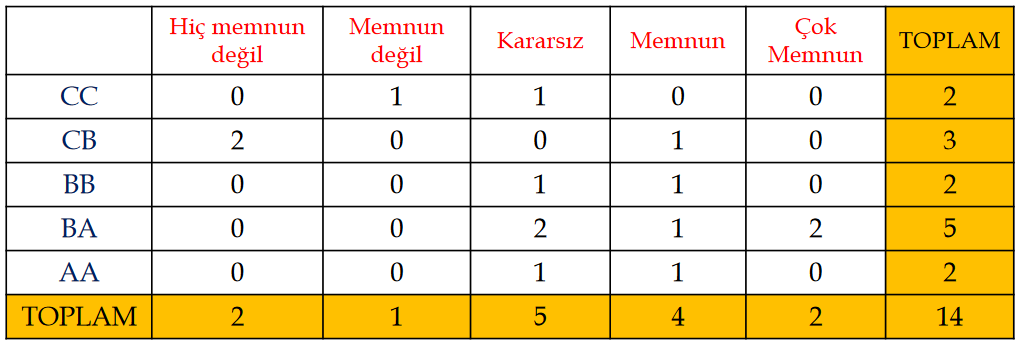
Not: Çapraz tablolardan soru gelebilir.
Aritmetik ortalama her değişken için kullanılabilir mi?
- Ölçme düzeyi en az eşit aralıklı olan değişkenler için hesaplanabilir. Diğer bir ifadeyle sınıflama ya da sıralama ölçme düzeyindeki değişkenler için hesaplanamaz.
- Hesaplama formülünde birimlerin tamamını kullanır. Dolayısıyla aykırı değerlerden etkilenir.
1, 10, 19 ortalaması=10
8, 10, 12 ortalaması=10
1, 2, 150 ortalaması=51
Medyan her değişken için kullanılabilir mi?
- En az sıralama düzeyinde ölçülen değişkenler için hesaplanabilir.
- Hesaplama formülü birimlerin tamamını kullanmaz. Bu nedenle uç değerlerden etkilenmez.
- Matematiksel işlemlere ortalama kadar uygun değildir.
- Birimlerin yarısı ortancadan küçük diğer yarısı ise ortancadan büyük değerler alır.
Mod her değişken için kullanılabilir mi?
- Sınıflama düzeyinde ölçülen değişkenler için hesaplanabilen tek merkezi eğilim ölçütüdür.
- Hesaplama formülü birimlerin tamamını kullanmaz. Bu nedenle uç değerlerden etkilenmez.
- Matematiksel işlemlere ortalama kadar uygun değildir.
Not: Bu Ortalama Medyan ve Mod dan soru gelir.
Merkezi Dağılım Ölçütleri Özellikleri
Birimlerin hangi değer etrafında toplandığını gösteren eğilim ölçütleri (ortalamalar) çoğu zaman yeterli bilgiyi sağlayamamaktadır. Örneğin A ve B hisse senetleri fiyatlarına ilişkin günlük ortalamaların eşit olduğunu varsayalım.
Bu durumda A ve B hisse senetleri için ortalama değerlerin kıyaslanması anlamlı olmamaktadır. Buna karşın hisse senedi fiyatları için ortalamalar aynı olsa da ortalama civarındaki dağılımları farklılaşacaktır. Hisse senedi fiyatı bakımından ortalama civarındaki dağılımı daha homojen (türdeş) olan zaman içerisinde daha istikrarlı bir seyir izlemektedir. Daha istikrarlı olan hisse senedi için risk azaldığından bu hisse senedinin tercih edilmesi uygun olacaktır.
Bir başka örnekte döviz kurları için verilebilir. Şöyle ki enflasyon hedeflemesi rejimi uygulayan Merkez Bankaları için döviz kurları serbest piyasada belirlenmektedir. Merkez Bankaları döviz kurunun değerine değil ancak kurlardaki oynaklığa (volatiliteye) bağlı olarak piyasaya müdahalede bulunmaktadır. Oynaklık kurların dağılımlarındaki genel gidişatın izlenmesi ile ölçülmektedir. Oynaklığın sayısal olarak ifadesi ise merkezi dağılım ölçütleri ile mümkün olmaktadır. Uygulamada en çok kullanılan merkezi dağlım ölçütleri varyans ve standart sapma ile değişim katsayısıdır.
HAFTA 7: Iş Zekâsi Ve Veri Görselleştirme
İş Zekası (BI-Business Intelligence)
Son 25 yıl içerisinde bilgi teknolojilerindeki gelişmelere bakıldığında ilk yıllarda en büyük önemin “veri toplanması” na verildiği söylenebilir. Yıllar boyunca verinin toplanması yönündeki yatırımlar hızla artmış, bu da verinin toplanması ile ilgili teknolojik gelişmeleri daha da hızlandırmıştır.
Buna paralel olarak toplanan verilerin saklanması ve güvenliği ile ilgili teknolojik gelişmeler de aynı hızla gerçekleşmiştir. Verilerin, bilgiye dönüşmesi ve ardından yöneticilerin vereceği kararlara temel sağlaması asıl hedef olduğundan, büyük miktarlarda toplanan verilerin arşivlenmesi, sorgulanması ve onlardan rapor üretilmesi gündeme gelmiştir. Günümüzde ise toplanan verilerin bir arada tutulabilmesi, ayrıştırılabilmesi, derlenmesi ve anlamlı bir hale getirilerek raporlanmasının önemi fark edilmiştir.
İş zekasını (verileri düzenleme, gruplama, analiz etme) hazırlayanlara Veri hazırlama ve raporlama uzmanı, veri analist uzmanı, veri bilimci, iş analisti deniyor. Bu meslek gruplarından birine sahip olanların bir miktar yazılım, veri tabanından bir miktar daha fazla, bir miktar istatistik bilmeleri gerekiyor. Birde bunların dışında bu verileri raporlayacak uzmanlar gerekiyor.
Yöneticilerin, kurumlarıyla ilgili strateji belirlemeleri, politika üretmeleri ve ihtiyacı olan bilgilere anında erişebilmeleri amacıyla ihtiyaç duydukları zeki karar destek sistemleri, iş zekâsı (BI-Business Intelligence) kavramını tarif etmiştir.
İş zekâsı, veri sürümlü KDS kapsamında yer alan ve kurumda oluşan operasyonel veriyi, amacına uygun ve kullanışlı bilgiye transfer ederek kullanıcılara sunulması işlemini gerçekleştiren bir uygulamadır. (TBD, 2010).
İş zekası, bütün kaynaklardan toplanan verileri, bilgiyi elde etmek için yeni formlara dönüştürmeyi amaçlayan, bilinçli, sistemli, işle ilgili ve sonuç odaklı işlemlerin bütünüdür (Biere, 2003).
Var olan iş performansını anlamak ve bilgiye dayalı iş kararları almak için tüm örgüt çapında iş verilerinin analizidir.
İş zekâsı, kurumların, işletmelerin verimliliğini veya karlılığını artırmaları, kararlarını en iyi şekilde verebilmeleri, ölçümlerini yapabilmeleri ve performansı ayarlayabilmeleri için bilginin doğru şekilde kullanılmasıdır.
Modern yönetim tarzlarında iş zekası olmazsa olmazlardandır.
İş Zekâsı Mimari Yapısı
Veri tabanı, sistematik erişim imkânı sunan, birleştirilmiş ve koordine edilmiş dosyalar kümesi olarak tanımlanabilir.
Veri ambarları ise iş zekâsı uygulamaları için alt yapı oluştururlar ve klasik veri depolama yöntemleri ile toplanan verilerin uzun süreli saklandıkları, ilişkili verilerin sorgulana bilindiği ve analizlerinin yapılabildiği veri depolarıdır.
Başka bir ifadeyle veri ambarı, bir işletmenin ya da kuruluşun değişik birimleri tarafından canlı sistemler aracılığı ile toplanan bilgilerin, gelecekte kullanılabilecek ya da değerlendirilebilecek olanlarının arka planda üst üste yığılarak birleştirilmesinden oluşan büyük çaplı bir veri deposudur. Bir veri ambarı, genellikle boyutların ve bu boyutlarla ilgili özelliklerin belirlediği değerleri barındıran hücrelere sahip bir çok boyutlu veri tabanı yapısıyla modellenir ve belirli bir amaç için organize edilir.
Veri ambarları, değişik kaynaklarda bulunan verilerle ilgili veri temizleme, aktarım, birleştirme, yükleme ve periyodik olarak güncelleme süreçleri ile inşa edilirler. Bu işlem ETL olarak bilinmektedir (Extract Transform Load). Veri madenciliği (VM) genel bir kabulle insan merkezli bir süreçtir.
VM, veri tabanı sahibine anlaşılır ve faydalı sonuçlar üretmek amacıyla büyük miktardaki verilerin, daha önceden bilinmeyen ilişki ve kuralların keşfedilebilmesi için modelleme, çıkarım ve seçim sürecidir.
Çevrim içi analitik işleme (Online Analytical Processing-OLAP) operasyonları kullanılarak birimler arasındaki ilişkinin keşfedilmesi sağlanabilir. OLAP çok boyutlu veri analizine işaret eder.
Çok boyutlu veri analizinde veri, değişik boyutlardan incelenir. Veri ve boyutları birlikte, küp olarak adlandırılmaktadır.
Iş Zekâsi ve Veri Görselleştirme
Çevrim içi analitik madencilik (Online Analytical Mining-OLAM) sunucusu very küplerinde çevrim içi işlemede OLAP sunucusunun çevrim içi işleme mantığıyla aynı performansı gösterir.
Meta-Veri, veri ambarının en önemli bileşenlerinden birisidir. Veri ambarında verilerin tanımlandığı kısımdır. Meta-veri “veri hakkında veri” şeklinde ifade edilebilir.
Verilerdeki elemanın anlamını, hangi elemanların hangileriyle nasıl ilişkili olduğunu ve kaynak verisi ile erişilecek veri gibi bilgileri içermektedir.
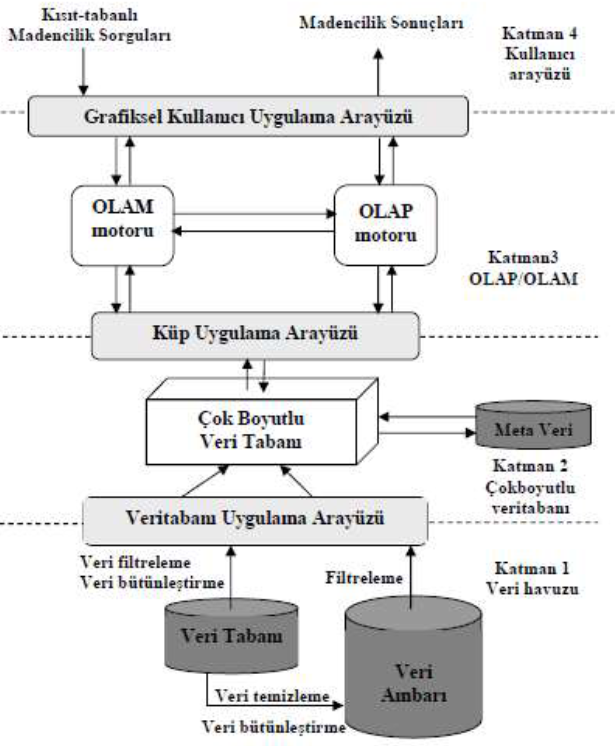
Veri Küpü
“Veri Küpü” terimi, veri ambarlama literatüründe sürekli olarak kullanılmaktadır. Bir veri kümesi; çok boyutlu hiper-karmaşık kavramsal modellemedir, ya da kısaca veri küpü’dür.
Kümedeki bir veri birimini tarifleyen d fonksiyonel özellikleri boyutlardır. d, boyutu göstermektedir. Bunların bazıları hiyerarşik (örneğin; zaman boyutunda yıl, çeyrek yıl, ay, gün gibi), bazıları var olan bir özellik için çoklu hiyerarşiye (örneğin yine zaman boyutunda hafta, gün gibi) sahiptir. Bir formdaki kayıtları oluşturan veri kümesi (d-tuple) değerleri çok boyutlu dizilerdeki bir hücreyi temsil etmektedirler.
Hücreler, ekstra özelliklerdeki değerleri içerirler (Riedewald, Agrawal and Abbadi, 2003).
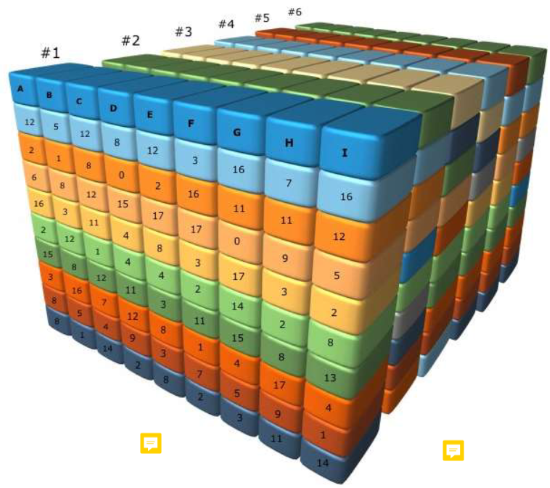
Tahmini olarak veri küpünün tasarımı.
Bu veri küpü 3 boyutlu olarak tasarlanmış. Python da 2 boyutlu yapılar DateFrame olarak adlandırılır. Tablo yapısıdır. Matematik ve istatistik tarafında bu 2 boyutlu tablolar matris olarak adlandırılır. Küpün ön yüzü gibi A,B, C,.. sütunları ve aşağıya inen satırlar. Bu tabloya #1, #2, #3 , … gibi yeni gruplar eklediğinizde 3 boyutu bir yapı olur. Bu boyutlara tensör denir.
Skaler denilen yönsüz nicel büyüklükler, vektör denilen yönlü büyüklükler ve matris denilen iki boyutlu nesneler birer tensördür. Tensör, tüm bu nesnelerin genelleştirilmiş halidir ve çok boyutlu veri kümeleri için kullanılır.
Veri görselleştirme:
Veri görselleştirmenin amacı, karmaşık bir veri tabanında neler olup bittiğini anlaşılır kılmaktır. İyi bir tanımlama, en azından, nereden başlamak gerektiği konusunda yol gösterici olabilir. Bulunan tanımlamaları göze hitap edecek bir şekilde anlamlandırabilmek de binlerce ilişki bulmaktan çok daha doğru bir resim ortaya koyabilir (TBD, 2010).
Veri görselleştirme yaklaşımlarında iki genel akım bulunmaktadır: Geleneksel ve Modern.
Veri göselleştirmede tabiki çeşitli grafikler kullanılır.
İnfografik: Baskıya uygun bir yapı. dinamiklik yoktur stabildir. Dashboard daha dinamik bir yapıdadır. hareketli unsurları vardır.
HAFTA 8: OYUN TEORİSİ
Hatırlatma: Temel Olasılık
Olasılık, bir şeyin olmasının veya olmamasının matematiksel değeri veya olabilirlik yüzdesi, değeridir.
Aristo’nun eserlerinde olasılık kavramı, bir gerçeğin rastgeleliğinin nicelikleştirilmesini (sayısallaştırılması) ifade etmektedir.
17. yüzyılın ikinci yarısında olasılık konusunun Blaise Pascal ve Pierre de Fermat tarafından matematiksel olarak incelenmeye başlanması ile olasılık sözcüğü modern anlamına doğru bir yol almıştır. Matematiksel modern olasılık kuramının geliştirilmesi 19. yüzyılda başlamıştır.
Olasılık genel anlamda bir kesir yapısı olarak karşımıza çıkmaktadır.
𝐴 / B
A = 𝐵𝑒𝑘𝑙𝑒𝑛𝑒𝑛 (𝐺𝑒𝑟ç𝑒𝑘𝑙𝑒ş𝑒𝑛) 𝑑𝑢𝑟𝑢𝑚𝑙𝑎𝑟𝚤𝑛 𝑠𝑎𝑦𝚤𝑠𝚤
B = 𝐺𝑒𝑟ç𝑒𝑘𝑙𝑒ş𝑚𝑒 𝑖ℎ𝑡𝑖𝑚𝑎𝑙𝑖 𝑜𝑙𝑎𝑛 𝑡ü𝑚 𝑑𝑢𝑟𝑢𝑚𝑙𝑎𝑟𝚤𝑛 𝑠𝑎𝑦𝚤𝑠𝚤
Bir yazı tura deneyi düşünülürse,
Toplam iki durum bulunmakta yazı veya tura gelmesi.
Yazı gelme olasılığı hesaplanmak istenirse, 1 / 2
Tura gelme olasılığı hesaplanmak istenirse, 1/2
Teorikte olasılığı 1/2 olsada deneysel olasılıkta bu tam gerçekleşmez. Ama deney sayısı artırılırsa teorik olasılığa yaklaşılır.
Bir zar deneyi düşünülürse,
Toplam altı farklı durum bulunmakta zarın üst yüzüne 1, 2, 3, 4, 5 veya 6 gelmesi.
3 gelme olasılığı hesaplanmak istenirse, 1/6
6 gelme olasılığı hesaplanmak istenirse, 1/6
Eğer gerçekleşmesi mümkün olmayan bir durumdan bahsedilirse bu durumun olasılığı 0’dır ve imkansız olay olarak adlandırılır.
Tersine, eğer gerçekleşmemesi mümkün olmayan bir durumdan bahsedilirse bu durumun olasılığı 1’dir ve kesin olay olarak adlandırılır.
Dolayısıyla olasılık değeri [0, 1] aralığında yer alan bir kesir değeridir.
Hatırlatma: Toplama Kuralı
Aynı anda gerçekleşmeyen (olasılıkları kesişmeyen/ayrık olayların) toplam gerçekleşme olasılığı, her olayın gerçekleşme olasılıklarının toplamına eşittir.
P(A veya B) = P(A) + P(B) P = olasılık
A veya B’nin Gerçekleşme Olasılığı = A’nın Gerçekleşme Olasılığı + B’nin Gerçekleşme Olasılığı
Örnek: Zarı attığımızda 3 veya 4 gelme olasılığı nedir?
Cevap: P(3) = 1/6 P(4) = 1/6
P(3 veya 4) = P(3) + P(4)
P(3 veya 4) = 1/6 + 1/6 = 1/3 çıkar.
Buradaki veya bağlacı önemli. İki olasılığın toplanmasını sağlar. Gerçekleşme ihtimali artar.
Hatırlatma: Toplama Kuralı (Ortak Olasılıklar)
P(A veya B) = P(A) + P(B) – P(A ve B) P = olasılık
A veya B’nin Gerçekleşme Olasılığı = A’nın Gerçekleşme Olasılığı + B’nin Gerçekleşme Olasılığı – A ve B’nin Gerçekleşme olasılığı (birlikte gerçekleşme olasılığı)
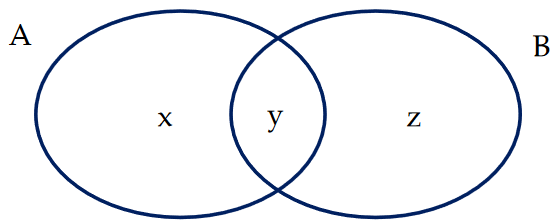
S(A) = x + y S(B) = y + z S(A veya B) = x + y + y + z
Örnek:
Bir sınıfta 27 erkek ve 23 kız toplam 50 öğrenci olsun. Sınavda 13 erkek ve 14 kız AA almıştır. Sınıftan rastgele bir öğrenci seçtiğimizde, bunun kız öğrenci veya AA alan öğrenci olma olasılığı nedir?
Cevap: Kız öğrenci AA almışta olabilir, almamışta olabilir. AA alan öğrenci kız da olabilir erkekte olabilir. Toplam 27 kişi AA almış. Toplam 23 kız öğrenci var. Hem kız hem AA almış öğrenci sayısı 14.
Erkek öğrenci oranı = 27 / 50 Kız öğrenci oranı = 23 / 50
Erkek öğrencilerin toplam öğrenciler içindeki AA alma oranı = 13 / 50
Kız öğrencilerin toplam öğrenciler içindeki AA alma oranı = 14 / 50
AA alan öğrencilerin toplam öğrencilere oranı = 27 / 50
Kız öğrenci veya AA alan öğrencilerin olasılığını sormaktadır. AA alan öğrencilerin içinde Kız öğrenci de vardır. Kız öğrenci veya AA alan öğrencilerden Kız öğrencileri çıkarmak gerekir.
P(Kız veya AA) = P(Kız) + P(AA) – P(Kız ve AA) => P(Kız veya AA) = P(23 / 50) + P(27 / 50) – P(14 / 50)
=> (50 / 50) – (14 / 50) = 36 / 50 = 72 / 100 bulunur.
Erkek öğrenci veya AA alan öğrencilerin olasılığını sorsaydı; AA alan öğrencilerin içinde Erkek öğrenci de vardır. Erkek öğrenci veya AA alan öğrencilerden Erkek öğrencileri çıkarmak gerekir.
P(Erkek veya AA) = P(Erkek) + P(AA) – P(Erkek ve AA)
=> P(Erkek veya AA) = P(27 / 50) + P(27 / 50) – P(13 / 50)
=> (54 / 50) – (13 / 50) = 41 / 50 = 82 / 100 bulunur.
HAFTA 9: WEKA UYGULAMASI
Weka veri analiz uygulmasıdır. Tamamen modüler bir tasarıma sahip olup, içerdiği özelliklerle veri kümeleri üzerinde görselleştirme, veri analizi, iş zekası uygulamaları, veri madenciliği gibi işlemler yapabilmektedir.
Makine öğrenimi amacıyla Waikato Üniversitesinde (Yeni Zelanda’da) geliştirilmiş ve “Waikato Environment for Knowledge Analysis” kelimelerinin baş harflerinden oluşmuş yazılımın ismidir. Makine öğrenimi algoritmalarını ve metotlarını içermektedir.
Java dilinde geliştirilmiş olması ve kütüphanelerinin .jar dosyaları halinde geliyor olması sayesinde, Java dilinde yazılan projelere kolayce entegre edilebilmesi kullanımını daha da yaygınlaştırmıştır.
Weka yazılımı, kendisine özgü olarak bir.arff uzantısı desteği ile gelmektedir. Ancak Weka yazılımının içerisinde CSV dosyalarını da ARFF formatına çevirmeye yarayan araçlar mevcuttur.
Temel olarak aşağıdaki 3 Veri Madenciliği işlemi Weka ile yapılabilir:
Sınıflandırma (Classification)
Bölütleme (Clustering) (kümeleme)
İlişkilendirme (Association)
Ayrıca yukarıdaki işlemlere ilave olarak, veri kümeleri üzerinde ön ve son işlemler yapılabilir
Veri Ön işleme (Data Pre-Processing)
Görselleştirme (Visualization)
Weka Kütüphanesi’nde veri kümelerini içeren dosyalar üzerinde çalışan çok sayıda hazır fonksiyon bulunmaktadır.
Weka uygulaması açık kaynak kodludur. https://waikato.github.io/weka-wiki/downloading_weka/
Linkinden indirilip kurulabilir. Yada arama motoruna weka yı aratıp sisteminize uygun versiyonu indirebilirsiniz. Kurulup çalıştırıldığında

Penceresi açılmaktadır. Açılan menülerden Explorer ve Experimenter menüleri işinizi yapmanıza yetecektir.
Explorer Menüsü:
Explorer menüsü tıklandığında,
Weka explorer pencersi açılmaktadır.
Varolan bir veri dosyası ile çalışmak için;
Weka à ExploreràOpen file tıklıyoruz. Açılan açılır pencereden;
C:(C sürücüsüne yüklendiği varsayılarak)àProgram Filesà Weka-3-8-6 (yüklediğiniz versiyona göre değişebilir)à data çift tıklanarak açılır. Bu işlemler open tuşu kullanılarak yapılırsa hata verebilir. (bende hata verdi). Data içinden hangi veri ile çalışmak istenirse seçilip open tuşu tıklanır, yada çift tıklanır.
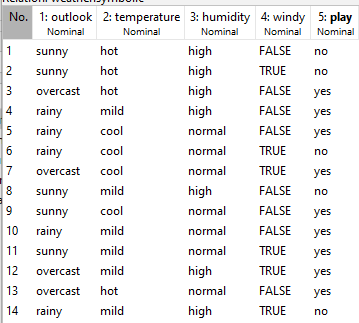
Biz weather.nominal.arff (nominal değişkenlerinin oluşturuduğu hava durumu) seçtik. Bu veri seti uygulamanın içinde zaten var olan bir veri dosyası.
Tıklandığında açılan pencerede outlook, temperature, humidity(nem), windy(rüzgarlı), play değişkenleri görülür. Hava durumu verileri üzerinden yola çıkılarak dışarıda tenis, futbol gibi bir oyun oynayıp oynayamayacakları bir yapı planlanıyor. Veri madenciliği, veri analizi yapılacak.
Outlok (görünüm-dışarısı) değişkeninde, sunny (güneşli), overcast(bulutlu), rainy(yağmurlu) seçenekleri var. yukarıdaki sağ üst taraftaki edit menüsüne tıklandığında
açılır.
1 ve 2. Değişkende play de no olmuş ve bu değişken play için doğrudan etkili değil.
HAFTA 10: WEKA UYGULAMASI
Uygulamada deneme yapmak için veri seti oluşturulması.
Weka’nın data içindeki .arff uzantılı dosyalarından biri güvenli bir yere kopyalanır. Orijinal dosyanın yerinde kalması için kopyası alınır. Kopyalanan yerde dosyanın üzerinde sağ tıkàbirlikte açàdiğer uygulamalarànot defteriàtamam seçilir.
Açılan not defterinde görülen % işaretlerinin olduğu yerler açıklama satırlarıdır. Bunları silip kendi açıklamamızı yazabiliriz.
% işaretlerinden sonra gelen ilk gelen @ işaretinde yazılı olan @relation tagı dosyanın adını oluşturuyor. Buraya veri1 yazalım. Karışmaması için altına bir tane boş satır ekleyelim.
@relation ‘in altında bulunan @attribute yapılar kriter yapılarıdır. Buradan verileri tanımlamamız lazım. Kategorik tanımlamaların {} küme parantezleri içinde virgül ile ayrılması gerekir. Kategorik tanımlama birden fazla ayrı kelimeden oluşuyor ise tek tırnak içinde string ifade olarak tanımlanması gerekiyor. Tek kelimeden olşuyor ise tırnak içine alınmıkyor. Numeric tanımlama yapılacak ise doğrudan numeric yazılması gerekiyor.
Oluşturacağmız veri setinin kriterleri:
- @attribute yas numeric
- attribute ogr_durumu {lise, onlisans, lisans, lisansustu}
- @attribute medeni {bekar, evli}
- attribute cinsiyet {kadin, erkek}
- @attribute gano numeric
- attribute bolum {optisyenlik, bilgisayar, grafik, isletme}
- @attribute DGS {kazandi, kazanamadi}
@attribute lerin altında @data ile başlayan yerlere verilerimizi girmemiz gerekiyor. kaç tane veri türü girilmiş ise @data bölümünde her satırda o kadar veri olması gerekiyor. yukarıdaki örnekte 7 veri türü var. @data bölümündeki satırların her birine 7 veri girilmesi gerekiyor. @data bölümündeki ilk satırda sırası ile yas, ogr_durumu, medeni, cinsiyet, gano, bolum, DGS verilerinin olması gerekir.
Excel de veri oluşturulması:
Veri türleri sütun başlıklarına yazılır. verileri hazırlamak için ikinci bir excel sekmesi(sayfası) açılır. Yaş seçmek için aralık belirlenir. 18-65 olsun. İkinci sayfada; =RASTGELEARADA(18;65) yazılıp 18 ile 65 arasında bir yaş seçmesi sağlanır. Kopyalanarak 120 satırlık veri oluşturalım. Her dokunduğunda değişeceği için dikkat edilmesi gerekir. yas değişkenin altına sağ tıklanıp sadece sayısal değerler yapıştırılır.
İkinci sayfadki formüllerin değerleri kopyalandıktan sonra silinir. İkinci veri türümüzdeki ogr_durumu ‘nda 4 değişken tanımlamaıştık. excel de =RASTGELEARADA(1;4) yazılıp 1 ile 4 arasında rastgele sayılar seçilir. Yine 120 satır veri oluşturulup sadece sayısal değerler yeni bir sütuna kopyalanıp formllü sütun silinir. Farklı bir hücreye tıklanıp tıklanıp Ctrl+F yapılır. çıkan pencerede değiştir seçilir. Aranan kısma 1 yazılır.
Yeni değer kısmına weka daki sırası ile lise yazılır. Tümünü Değiştir seçilir. 1 olan hücrelerin hepsi lise ile değiştirilir. Ayni şekilde 2 ler onlisans ile değiştirilir. 3 lisans ile 4 lisansustu ile değiştirilir. Kopyalanıp sadece değerler ogr_durumu sütununa yapıştırılır. Aynı işlemler medeni, cinsiyet, bolum ve DGS sütunları içinde yapılır.
gano değeri normalde 0 ile 100 arasında değişir. Mezuniyet için not ortalmasının 70 ve üzerinde olması gerekir. Dolayısı ile notlar 70 ile 100 arasında olacak ve virgülden sonra 2 basamaklı hassasiyet olacak. normalde formülü =RASTGELEARADA(70;100) şeklinde yazmamız gerekiyordu. 2 virgülden 2 basamka istediğimiz için =RASTGELEARADA(7000;10000)/100 şeklinde yazıyoruz.
Buraya Dikkat
excel verilerini oluşturduktan sonra excel sayfasında DosyaàFarklı Kaydetàkayıt edilecek dosya tıklıyoruz. Açılan pencerede Kayıt türü nü CSV (Virgülle ayrılmış) seçiliyor. Aynı klasör içine kayıt ediliyor. Veri2.csv dosyasının üzerinde sağ tıkàbirlikte açàdiğer uygulamalarànot defteriàtamam seçilir.
Açılan not defterinde Düzenle(yada Düzen)àDeğiştir tıklanır. Açılan pencerede üst tarafa(Aranan) , alt tarafa(Yeni değer) . yazılır. Tümünü Değiştir tıklanır. Tümünü Değiştir dedikten sonra üst tarafa ; yazılır, alt tarafa , yazılır, Tümünü Değiştir seçilir. Başlık kısmı (yas,ogr_durumu yer aldığı satır) silinir.
Geri kalan kısmın tümü seçilerek kopyalanır. .arff uzantılı dosya sağ tıkàbirlikte açàdiğer uygulamalarànot defteriàtamam seçilirek açılır. Kopyalanan veriler @data tagının altına yapıştırılır. Kayıt edilir. Weka programında Explorer menüsünden oluşturduğumuz .arff uzantılı veri dısyası açılır.
HAFTA 11: SPSS.25 Uygulaması
Dosya uzantısı .sav
Korelasyon analizi
Yaş artıkça tecrübede artar mı. Dolar kuru arttınca, altın fiyatları artar mı gibi ilişkileri analiz eder. bu değişkenler arasındaki ilişkiyi analiz eder.
x ile y arasında aynı yönde, x ile z arasında ters yönde ilişki var. Korelasyon katsayısı değeri 1 ile -1 arasında değerler alır. İki değişkenin korelasyon katsayısı (0) sıfıra yakın ise bu iki değişken arasındaki ilişki neredeyse yok denecek kadar azdır. (0) Sıfıra eşit ise ilişki yoktur demektir. (0) sıfıra yakınlığı 0,3 ‘ten daha düşük değerler olarak kabul ediliyor.
İki değişken arasındaki korelasyon katsayısı 1 ‘e çok yakın ise 0,95 gibi bu iki değişken arasında çok kuvvetli ve pozitif ilişki var demektir. Aynı yönde hareket ediyorlar.
İki değişken arasındaki korelasyon katsayısı -1 ‘e çok yakın ise -0,95 gibi bu iki değişken arasında çok kuvvetli ve negatif bir ilişki var ama demektir. Yani ters yönlerde benzer hareket ediyorlar.
Sayfa 9-10: Cevabı 11.hafta ödevinde var.
Sayfa 11: 0,7 < r güçlü ilişki
0,31 < r < 0,7 orta ilişki
0 < r < 0,3 zayıf ilişki
HAFTA 12: DOĞRUSAL REGRASYON
Herhangi bir zaman serisi üzerinde bağımlı(açıklanan) yada bağımsız(açıklayıcı) değişken arasındaki ilşkiyi bir tahmin modeli kullanarak açıklayan en basit ve en tutarlı olan yöntemlerden birisidir.
katsayısı grafikteki doğrunun eğimini verir. katsayısı doğrunun konumunu belirler.
x ‘in i gözleminden x ‘in ortalaması çıkarılır. y ‘nin i gözleminden y ‘nin ortalaması çıkarılır. x ve y’nin çıkan sonuçları birbiri ile çarpılır. Bütün gözlemlerin çarpım sonuçları toplanır. Bu şekilde pay kısmı bulunur. x ‘in i gözleminden x ‘in ortalaması çıkarılarak bulunan sonucun karesi alınarak sonucların tümü toplanır. Bu şekilde de payda bulunur. Payın paydaya bölümünden değerini buluyoruz.
y nin ortalamasından ile x ‘in ortalamasının çarpımını çıkardığımızda da buluyoruz.
Yorum Bölümü
Eklenmesini istediğiniz içerikleri; ders notları, sınav soruları ve program kurulum talimatları gibi içerik isteklerini yorum kısmında belirtirseniz en kısa zamanda eklerim. Yorumlarda yazdığınız e-postanız Gizlilik İlkemiz gereği kesinlikle yorumlarda yayınlanmıyor. Hiçbir kurum veya kişi ile paylaşılmıyor. Reklam e-postaları gönderilmiyor. E-posta doğrulaması yapılmıyor. Sadece yorumlarınız için geri bildirimde bulunmak için isteniyor.
- Bilgisayar Donanımı Soruları
- Bilgi Güvenliği Soruları
- Bilgisayar Ağları Soruları
- Bilgisayarla İstatistik Uygulamaları
- Ofis Yazılımları Soruları
- Uşak Üni. Harf Notu Hesapla
- İstanbul Üni. Harf Notu Hesapla
- Yazılım ve Kodlama Özel Ders
- Web Sitesi Yapımı
- Veri Nasıl Kurtarılır
- Win 10 da Güvenli Mod
- Green Card Başvuru Ne Zaman
- Green Card Başvuru Sonuçları
- Gizlilik İlkelerimiz
- İletişim Bilgileri
- Ahmet Uluca Hakkında
- Ana Sayfa
Hi,
I analyzed your WordPress site and found critical optimization errors and very slow loading times that could be hurting your SEO and driving visitors away.
I’m Emily—WordPress speed optimization expert.
Let me know by replying, and I’ll share your free report.
Thanks,
Emily
Hi Emily,
Thank you for your concern. I am fixing the problems on my website myself and I do not need your services at this time. I will contact you when I need it.
Hi,
I just visited ahmetuluca.com and wondered if you’d ever thought about having an engaging video to explain what you do?
Our videos cost just $195 for a 30 second video ($239 for 60 seconds) and include a full script, voice-over and video.
I can show you some previous videos we’ve done if you want me to send some over. Let me know if you’re interested in seeing samples of our previous work.
Regards,
Joanna
Hi Joanna,
I do not make money from my ahmetuluca.com site. Therefore, I do not plan to create videos. Your e-mail address is registered here for me to reach you. I will contact you when I think of making money from my ahmetuluca.com site.
Hi there,
We run a YouTube growth service, which increases your number of subscribers both safely and practically.
– We guarantee to gain you 700-1500+ subscribers per month.
– People subscribe because they are interested in your channel/videos, increasing likes, comments and interaction.
– All actions are made manually by our team. We do not use any ‘bots’.
– Channel Creation: If you haven’t started your YouTube journey yet, we can create a professional channel for you as part of your initial order.
The price is just $60 (USD) per month, and we can start immediately.
If you have any questions, let me know, and we can discuss further.
Kind Regards,
Felicity
Hi Felicity
Thank you for the information. But I am not producing content for Youtube for now. I will contact you when I start producing content for Youtube.
I wish you success.
Ahmet Uluca
Hi there,
We run a YouTube growth service, which increases your number of subscribers both safely and practically.
– We guarantee to gain you 700-1500+ subscribers per month.
– People subscribe because they are interested in your channel/videos, increasing likes, comments and interaction.
– All actions are made manually by our team. We do not use any ‘bots’.
– Channel Creation: If you haven’t started your YouTube journey yet, we can create a professional channel for you as part of your initial order.
The price is just $60 (USD) per month, and we can start immediately.
If you have any questions, let me know, and we can discuss further.
Kind Regards,
Katelyn
Hi Katelyn
Thank you for the kind offer. But I’m not thinking about it right now. I’ll reach out when I do.
Hi there,
We run a Youtube growth service, where we can increase your subscriber count safely and practically.
– Guaranteed: We guarantee to gain you 700-1500 new subscribers each month.
– Real, human subscribers who subscribe because they are interested in your channel/videos.
– Safe: All actions are done, without using any automated tasks / bots.
Our price is just $60 (USD) per month and we can start immediately.
If you are interested then we can discuss further.
Kind Regards,
Amelia